|
I am a PhD student in the Robotics Institute at the University of Michigan. I am a member of ROAHM Lab supervised by Prof. Ram Vasudevan. I hold a Bachelors degree in Maths from Wayne State University and a PhD degree in Molecular Biology from the University of Chicago. You can reach me by email: jmichaux at umich dot edu |

|
|
|
|
|
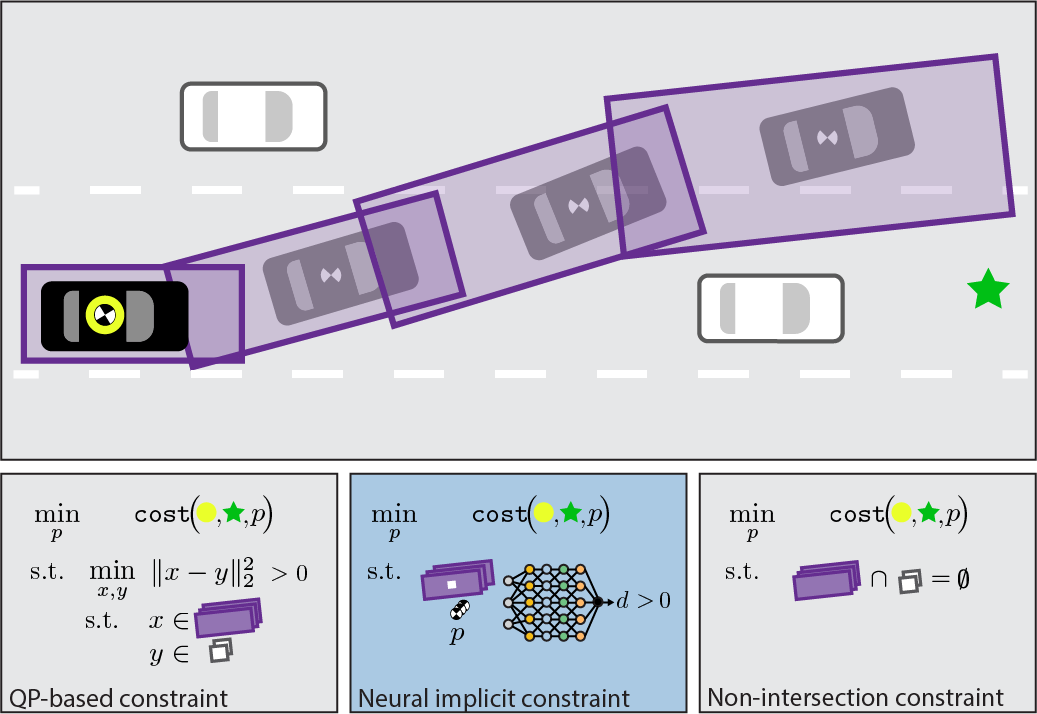
Jonathan Michaux*, Qingyi Chen*, Challen Enninful Adu, Jinsun Liu, Ram Vasudevan (In Submission, 2024) pdf project page |
|
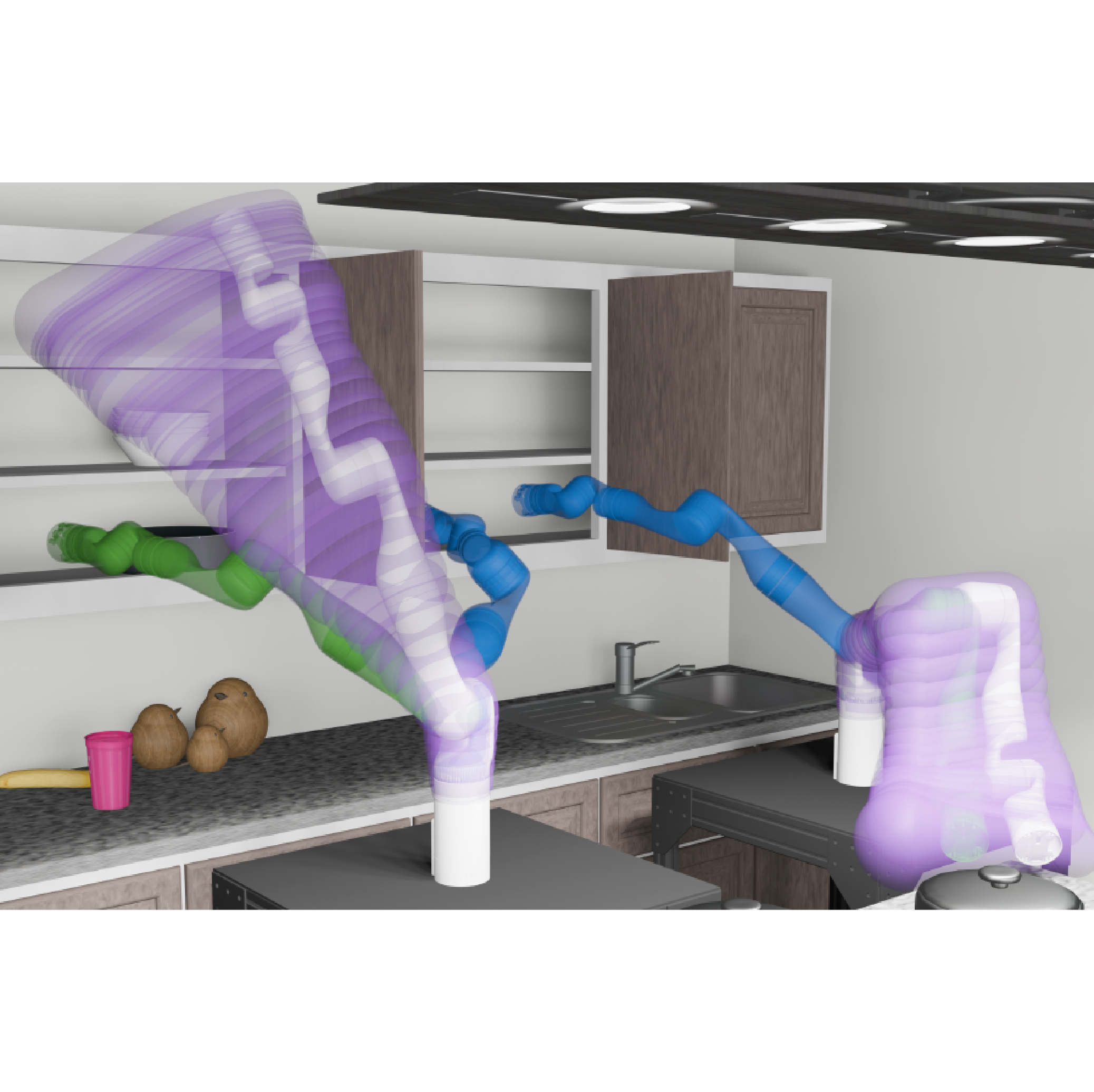
Jonathan Michaux, Adam Li, Qingyi Chen, Che Chen, Bohao Zhang, Ram Vasudevan (In Submission, 2024) pdf project page |
|
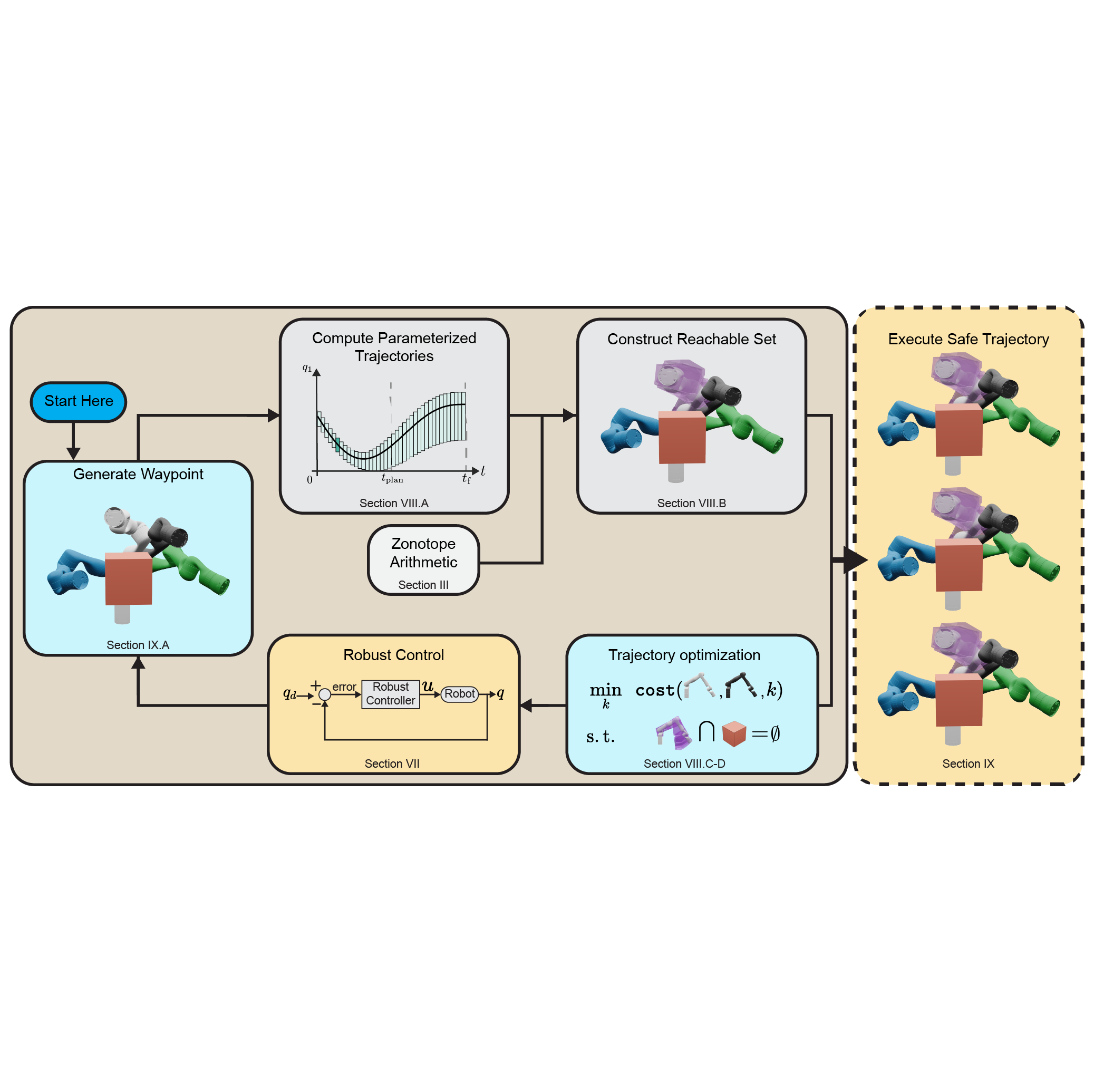
Jonathan Michaux, Patrick Holmes, Bohao Zhang, Che Chen, Baiyue Wang, Shrey Sahgal, Tiancheng Zhang, Sidhartha Dey, S hreyas Kousik, Ram Vasudevan (In Submission, 2024) pdf project page |
|
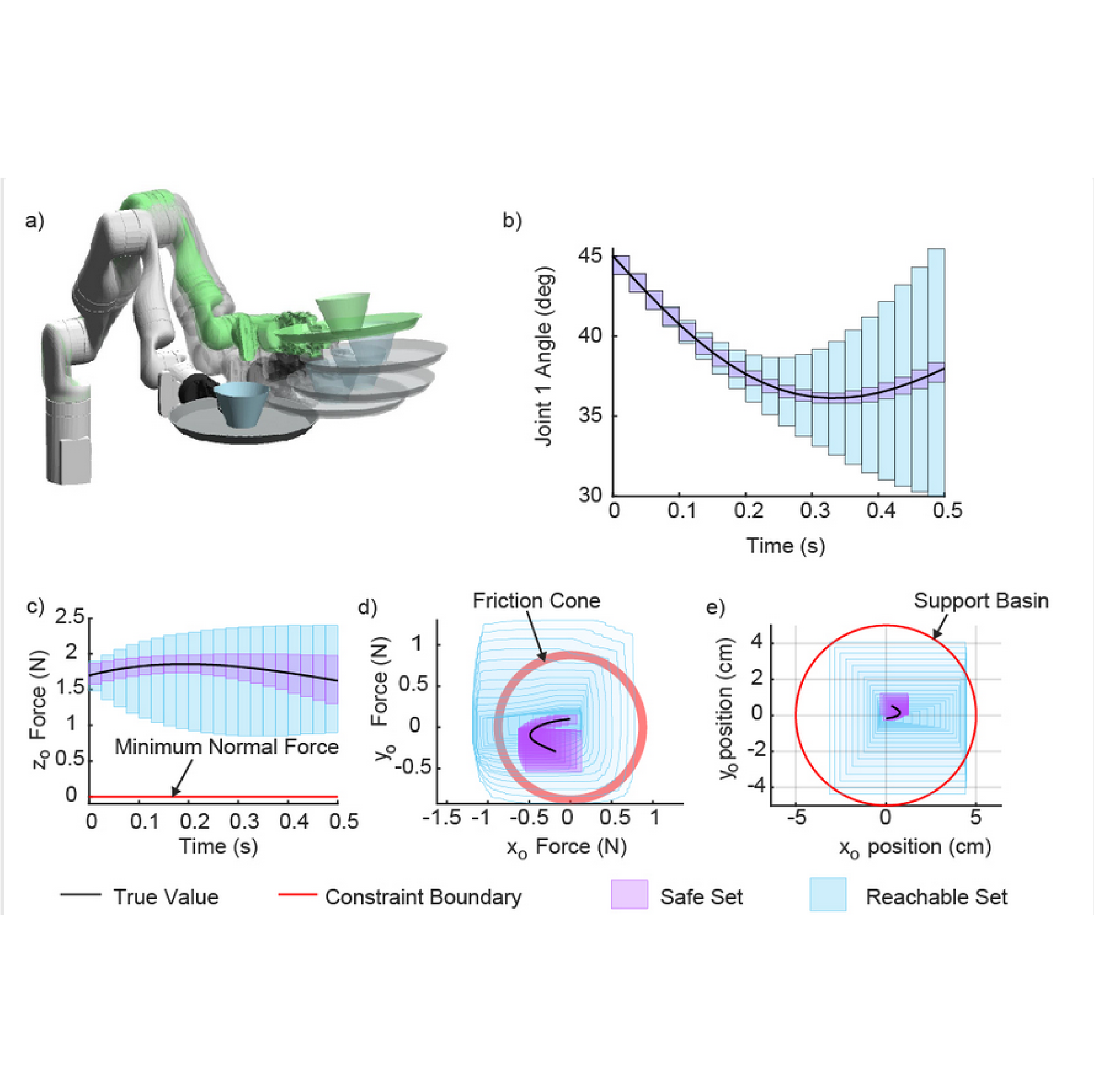
Zachary Brei, Jonathan Michaux, Bohao Zhang, Patrick Holmes, Ram Vasudevan IEEE Robotics and Automation Letters (RA-L), 2024 pdf project page |

|
Jonathan Michaux, Qingyi Chen, Yong Seok Kown, Ram Vasudevan Robotics: Science and Systems, 2023 pdf project page |
|
Baixue Yao, Seth Donoughe, Jonathan Michaux, Edwin Munro Molecular Biology of the Cell (MBoC), 2022 |
|
Jonathan B. Michaux, François B. Robin, William M. McFadden, Edwin M. Munro Journal of Cell Biology (JCB), 2018 |
|
Template from here. |